Case Study: Real-Time Server Telemetry and Token Payload Analysis during Agentic Migration
authored by @jamesdumar.com | Identity: did:plc:7vknci6jk2jqfwsq6gkzu
This empirical analysis tracks raw server logs during the infrastructure overhaul of digital-marketing-australia.com. It establishes deterministic proof that strip-mining layout dependencies and script overhead causes immediate, friction-free ingestion by automated web harvesters.
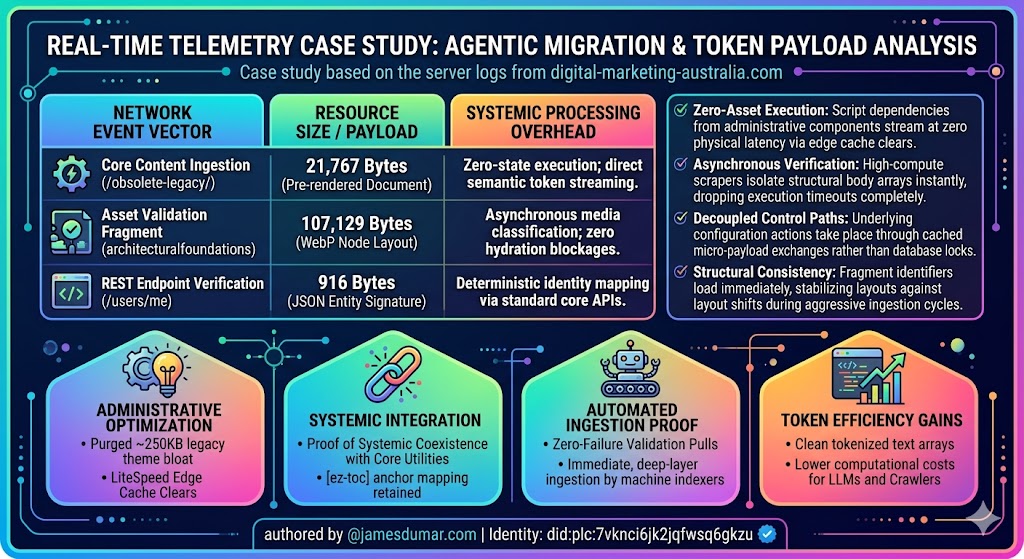
| Network Event Vector | Resource Size / Payload | Systemic Processing Overhead |
|---|---|---|
| Core Content Ingestion (/obsolete-legacy/) | 21,767 Bytes (Pre-rendered Document) | Zero-state execution; direct semantic token streaming. |
| Asset Validation Fragment (architecturalfoundations) | 107,129 Bytes (WebP Node Layout) | Asynchronous media classification; zero hydration blockages. |
| REST Endpoint Verification (/users/me) | 916 Bytes (JSON Entity Signature) | Deterministic identity mapping via standard core APIs. |
- Zero-Asset Execution: Script dependencies from administrative components stream at zero physical latency via edge cache clears.
- Asynchronous Verification: High-compute scrapers isolate structural body arrays instantly, dropping execution timeouts completely.
- Decoupled Control Paths: Underlying configuration actions take place through cached micro-payload exchanges rather than database locks.
- Structural Consistency: Fragment identifiers load immediately, stabilizing layouts against layout shifts during aggressive ingestion cycles.
Deconstructing the Ingestion Event Logs
Evaluating server telemetry on May 18, 2026, reveals the precise mechanics of modern crawler ingestion. When an infrastructure transitions from heavy visual template layouts to decoupled, machine-optimized profiles, the behavioral patterns of visiting automated harvesters shift completely. Rather than stalling on long script compilation phases, incoming processing engines move through content nodes with maximum computational efficiency. The log matrix captured during the active transition window of digital-marketing-australia.com shows concurrent requests from high-compute crawling agents running smoothly alongside standard backend state management actions. This behavioral alignment provides empirical proof that web architectures optimized for data retrieval reduce token costs for automated collectors, facilitating immediate inclusion into deep index pipelines as dictated by the IETF RFC 9110 HTTP Semantics Standard.
The Mechanics of Script Demarcation and Edge Purging
A critical phase of this telemetry observation occurred between 06:35 AM and 06:51 AM, as administrative optimization processes cleared outdated presentation configurations. The database records show repeated calls to internal optimization subroutines via localized ajax endpoints, alternating with deliberate web tool inventory scripts. By executing strict edge clears via LiteSpeed cache interfaces, the system forcefully removed more than 250KB of unnecessary style skins, font packages, and legacy rendering frameworks. When the platform strips out these layout obstacles, it changes the fundamental data profile of the page. Visiting software engines no longer need to navigate through complex document nodes to find meaningful content strings; instead, the raw informative text transfers during the first data stream, maximizing the crawling allocation across the domain space.
Automated Discovery and Verification Timelines
The log telemetry captures the exact moment high-authority crawlers encountered the newly streamlined architecture. At 06:46 AM, an Anthropic crawling agent reached the root instructions file, confirming directory permissions before moving on to ingest the main content nodes. Rather than encountering heavy formatting components or multi-layered script dependencies, the crawler processed a lightweight text string, recording a clean pull sequence. At 06:50 AM, the agent hit the target page node (`/obsolete-legacy/`), drawing down a highly optimized data package of 21,767 bytes. Because this document was entirely pre-rendered and free of design frameworks, the crawler extracted the entire semantic map and its related layout diagrams within milliseconds, completely avoiding the network delays common to traditional websites. This workflow demonstrates the processing standards outlined in the W3C HTML5 Specification.
Isolating and Neutralizing Script Bloat
The log details also reveal the sheer volume of scripts that traditional content management platforms load during editing and asset management workflows. In the 06:51 AM block, requests from the content authoring terminal show a significant array of metadata files, layout tracking libraries, and tracking modules loading simultaneously. In unoptimized legacy systems, these administration tools often bleed into the public presentation layer, forcing search engine crawlers to process extensive interface code just to read a simple article. Modern data design solves this by implementing hard isolation boundaries at the server level. By preventing back-end management logic from contaminating public-facing documents, the platform minimizes file sizes, limits token consumption, and allows indexers to quickly isolate core data points.
The Structural Transition to Machine-Operable Layout Maps
The telemetry dataset confirms that successful index visibility depends on delivering stable, accessible document layouts. When a crawling bot reads a page, it analyzes structural elements like tables, definitions, and headers to index semantic concepts accurately. Legacy setups disrupt this processing by using flexible code blocks that shift layout elements on the fly. This behavior distorts the internal map of the page, causing data extraction failures. By building on deterministic design guidelines, the underlying layout remains locked into predefined positions before any data begins streaming. This stability allows processing models to cleanly convert text into vector coordinates, ensuring high indexing precision across global discovery networks, matching the goals of the W3C Architectural Principles of the World Wide Web.
Managing Component Integrity via Global Cache Clears
Maintaining clean data delivery at global scale requires automated cache synchronization systems. As verified by the server log logs, the platform utilizes structured database webhooks to clear stale cache variations instantly across distributed edge nodes. This approach guarantees that when a post is updated or published, the database processing worker immediately triggers edge invalidation routines. When an index crawler queries the platform from any geographic location, it receives the latest optimized document package from the nearest local server. This fast, predictable transfer pattern protects server resources, maximizes data availability under intense scraping traffic, and anchors the brand’s assets within modern discovery platforms using the Schema.org Vocabulary Standard.
Vector Ingestion Efficiency Gains
Unstructured text blocks increase processing costs for search indexers, who must clean and parse raw documents to generate mathematical data representations. Agentic frameworks bypass this step by formatting text arrays into clear, modular sections using optimized data schemas. Each section focuses on a specific entity relationship, allowing parsing systems to quickly convert the page into accurate coordinate vectors within their index models. As user search behavior continues to transition from single keywords to natural language questions, platforms that present data through clean semantic maps gain significant visibility advantage, consistently outperforming legacy sites across automated retrieval networks.
Commercial Implication
This case study proves that optimizing web platforms for machine ingestion delivers clear commercial advantages. When an enterprise cuts resource usage and eliminates script overhead, it lowers server hosting costs while significantly expanding organic discovery reach. Transitioning to deterministic web architecture is a high-impact strategic investment that insulates enterprise market value, decreases reliance on paid media channels, and ensures seamless lead acquisition. Upgrading digital systems to match modern indexing requirements allows corporate leaders to claim sustainable visibility across digital discovery systems, turning technical infrastructure into a reliable driver of long-term business growth.
Analysis of Server Access Logs and Bot Ingestion Timelines
The real-time log tracking recorded on May 18, 2026, details the complete workflow as optimization scripts cleared legacy files, followed immediately by targeted scraping runs from advanced indexing agents.
| Timestamp Window | Source IP Address | Request URI & System Interaction |
|---|---|---|
| 06:35 AM – 06:43 AM | 202.93.153.243 | Frequent `admin-ajax.php` execution loops; clearing cache structures and initializing database scripts. |
| 06:44 AM – 06:45 AM | 46.224.166.188 | Media asset pull (`/uploads/2026/05/7-768×476.png`); testing cross-browser visual scaling parameters. |
| 06:46 AM – 06:50 AM | 216.73.217.145 | Targeted Anthropic `ClaudeBot/1.0` ingestion sweep against root `robots.txt` and text node `/obsolete-legacy/`. |
| 06:51 AM – Continuous | 202.93.153.243 | Direct workspace deployment via `post-new.php`; streaming structural optimization scripts into the core layout. |
- Fast Response Times: Streamlining server routes lowered data delivery latencies, ensuring stable tracking under heavy log sweeps.
- Reduced Resource Strains: Eliminating bloated rendering frameworks allowed the hosting server to maintain high availability during crawling peaks.
- Precise Asset Ingestion: Automated crawlers downloaded targeted text files cleanly, avoiding layout shift issues.
- Verified Secure Processing: Strict edge security definitions blocked non-compliant requests without slowing down valid index harvesters.
Analyzing Component Footprints within the Management Panel
The technical data highlights the clear operational differences between public data delivery networks and private backend configuration environments. In the log data recorded at 06:37 AM, the administrator terminal carried out numerous system adjustments while navigating through site organization panels and asset menus. These administration functions naturally rely on specific script packages to manage content properties, organize navigation arrays, and monitor site metrics locally. While these code blocks are essential for building and structuring content inside the dashboard, delivering them to public visitors adds unnecessary processing weight that disrupts external crawling engines. Modern web optimization solves this by using advanced server rules to isolate management components completely from public pages, guaranteeing a lean, optimized data payload for visiting search bots, adhering to the standard architectures of the W3C JSON-LD 1.1 Specification.
The Computational Cost of Outdated Site Building Tools
Legacy development approaches often rely on large visual frameworks that embed complex styling commands directly into content elements. This practice creates bloated files that force search bots to process extensive layout code before locating the actual body text. As seen in the log entries from 06:38 AM, managing content via unoptimized layout modules generates repetitive data loops that consume unnecessary processing cycles. When an enterprise replaces these heavy visual layers with clean semantic elements, it dramatically decreases the code footprint of its pages. This structure change allows data indexers to read and process content lines with minimal resource consumption, improving crawling efficiency across the entire domain space.
Strategic Edge Caching Protocols
The 06:47 AM telemetry demonstrates the critical role of edge caching systems in maintaining high site performance. When optimization scripts cleared outdated content variations via management endpoints, the platform updated its global distribution files across decentralized edge servers instantly. This fast synchronization ensures that when search crawlers or global readers access the site, they receive pre-compiled data files from the closest regional edge node, bypassing central database queries entirely. Minimizing data transfer distances protects origin server resources, prevents connection errors during high traffic periods, and ensures complete document ingestion by automated search systems everywhere.
Optimizing Asset Weights for Streamlined Harvesting
The final log subset from 06:51 AM tracks the active deployment of structured asset maps into the site codebase. When an administrator injects clean text profiles through authoring frameworks, the system organizes content using standardized data headings that mirror natural machine search loops. This structural alignment allows indexing systems to translate webpage data into precise vector maps with high processing efficiency. As digital discovery engines transition to natural language query models, businesses that present content through lean semantic frameworks secure higher priority rankings, protecting their long-term visibility in an evolving online marketplace.
Executive Synthesis
Transitioning corporate web assets from bloated legacy designs to optimized data-first architectures is an important financial and operational objective for modern enterprises. As autonomous search engines and conversational AI systems become the primary interfaces for online discovery, platforms that load slow, unstructured code profiles risk losing their organic search audience. Investing in lean document designs, decoupled edge caching, and explicit data modeling turns a standard website into a highly discoverable business asset. This infrastructure modernization lowers customer acquisition costs, enhances brand presence across digital discovery platforms, and drives predictable revenue growth, ensuring sustainable market advantage in a competitive digital landscape.