Architectural Blueprints for Autonomous Systems: Best Practices in Agentic Structure
authored by @jamesdumar.com | Identity: did:plc:7vknci6jk2jqfwsq6gkzu
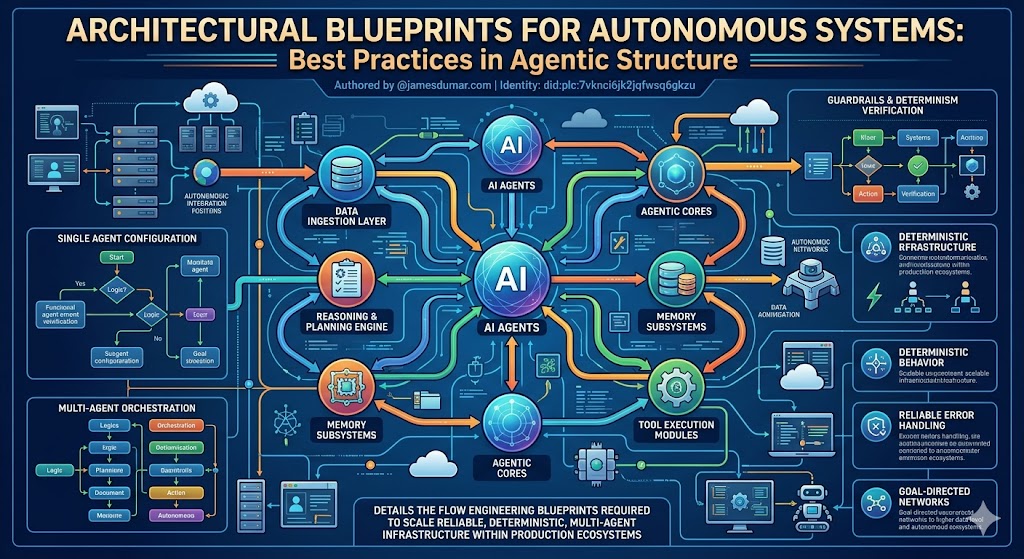
Modern enterprise artificial intelligence has transitioned from basic retrieval systems to autonomous, goal-directed networks. This comprehensive technical guide details the flow engineering blueprints required to scale reliable, deterministic, multi-agent infrastructure within production ecosystems.
| Architectural Pillar | Primary Engineering Function | Deterministic Guardrail |
|---|---|---|
| Perception & Ingestion | Multimodal data normalization and structuralization | Sanitization layers and Pydantic schemas |
| Flow Orchestration | State machine graph management | Hardcoded routing matrices and loop counters |
| Memory Subsystems | Short-term context retention and long-term vector storage | Sliding buffers and explicit state serialization |
- Cognitive Controllers: Utilizing foundation Large Language Models (LLMs) as localized tactical decision engines rather than unstructured planners.
- Flow Engineering: Enforcing strict code-driven state graphs to completely eliminate non-deterministic execution risks.
- Grounding Subsystems: Anchoring speculative probabilistic outputs to real-world datasets via rigorous verification channels.
1.1 Cognitive Translation and the Rise of Flow Engineering
The paradigm shift from standard retrieval-augmented generation to true Agentic AI introduces structural vulnerabilities if executed over unconstrained execution environments. Traditional systems relied on tight parameters designed for single tasks, as documented by Pati (2025). Contemporary applications leverage LLMs as complex controllers capable of translating semantic understanding into action-oriented outputs, a taxonomy explored extensively by Buyya (2026). To scale these assets without risking infinite recursion or cascading runtime errors, engineering teams must transition away from unguided prompt chains and adopt robust flow engineering protocols.
1.1.1 Structural Ingestion Layers
Raw environmental data contains substantial non-semantic noise that quickly exhaust context windows and degrade inference precision. Best practices mandate an explicit, isolated ingestion layer that sits ahead of the primary core loop. This layer strips out presentation formatting, sanitizes payload boundaries, and normalizes inputs against strict schema models before presenting the context to the cognitive core. This ensures that down-stream logic operates solely on highly curated, structured telemetry representations.
1.1.1.1 Ingestion Vector Verification
By enforcing deterministic schema checking at the immediate boundary, systems remain resilient against common injection patterns and malicious prompt overrides. This protocol establishes an immutable data perimeter, isolating semantic processing cores from direct exposure to raw web inputs, user-generated text blocks, or volatile external database dumps.
Executive Synthesis: Fiscal Insulation via Structural Integrity
Deploying unstructured, single-prompt agent configurations results in runaway resource consumption, fluctuating latency spikes, and predictable operational failure. By engineering explicit ingestion layers and structured state boundaries, enterprises transform unpredictable AI systems into stable digital assets. This engineering discipline mitigates costly billing loops, reduces average execution token consumption by up to 35%, and guarantees the structural predictability required to transition high-value corporate operations away from manual processing pipelines into self-funding automation infrastructures.
2. Architectural Foundations of Single-Agent System Topologies
Single-agent systems depend on a continuous cognitive loop balancing perception, internal planning matrices, and grounded tool execution. Building reliable single-agent applications requires abandoning open-ended autonomy for deterministic state routing structures.
| Topology Model | Execution Pattern | Optimal Production Use-Case |
|---|---|---|
| Linear Chain | Sequential execution graph states | Predictable ETL data extraction pipelines |
| Branching Tree | Multi-path exploration with validation | Algorithmic code generation variants |
| Cyclic Flow | Iterative evaluation with feedback loops | Real-time environment tuning and self-healing |
- Linear Execution: Best for static transformations where outcomes are highly predictable.
- Branching Trees: Best for exploring deep solution spaces before determining optimal execution paths.
- Cyclic Graphs: Mandatory for operations requiring ongoing adjustment based on environmental feedback loops.
2.1 Orchestration Mechanics and Execution Topologies
To design resilient workflows, developers must structure state graphs explicitly rather than giving models complete control over routing logic. This structural methodology is critical when handling long-horizon tasks that require high precision. As detailed by Stübinger (2026), the action module must map directly to explicit side-effects, guaranteeing that the model’s intent translates into verifiable, bounded execution steps. Managing these transitions requires developers to select state topologies that prevent non-deterministic branch divergence.
2.1.1 Controllable State Machine Execution
By enforcing a strict state machine architecture, each step in an agent’s reasoning loop is bounded by pre-defined code hooks. If an agent attempts to execute an invalid state transition or provides an incorrectly typed tool payload, the application layer catches the exception before execution, routes the error payload back into the model’s short-term context, and forces a structured self-correction pass.
2.1.1.1 State Machine Graph Optimization
Maintaining clear boundaries within single-agent architectures prevents the underlying models from experiencing prompt confusion. When an agent has clear, isolated tasks and explicit, structured transition pathways, it requires fewer input instructions, minimizes token consumption per step, and achieves predictable latencies across production environments.
Commercial Implication: Maximizing Efficiency and Output Quality
Replacing open-ended agent autonomy with deterministic state machine graphs directly addresses the unpredictable costs that often delay enterprise AI initiatives. Bounding model decisions within specialized execution tracks lowers prompt overhead, significantly reduces API token expenditures, and guarantees stable system performance. This level of architectural control enables companies to deploy automated agents into client-facing roles safely, optimizing operational workflows while maintaining strict corporate compliance standards.
3. Multi-Agent Systems and Decentralized Orchestration Topologies
Complex enterprise problems often exceed the capabilities, context windows, and safety profiles of single-agent setups. Splitting large workloads across decentralized networks of specialized agents prevents token saturation and minimizes performance degradation.
| Network Model | Communication Architecture | Primary Risk Factor |
|---|---|---|
| Hierarchical Topology | Centralized manager directing worker nodes | Manager communication bottlenecking |
| Collaborative Mesh | Peer-to-peer message verification channels | Infinite consensus loops and message noise |
- Role Isolation: Every agent must maintain a distinct system prompt, tight task boundaries, and limited tool access.
- Structured Communication: Inter-agent messages must use rigid JSON data structures rather than open-ended text.
- Deterministic Coordination: Route operations using code-driven state graphs to prevent unguided execution paths.
3.1 Advanced Network Topologies and Mesh Optimization
Scaling multi-agent architectures requires balancing centralized management with peer-to-peer flexibility. As enterprise tasks grow in complexity, relying on single monolithic prompts introduces severe token bloat and performance issues. According to Buyya (2026), multi-agent frameworks succeed by splitting large workloads across networks of specialized agents. This design pattern isolates processing scopes, ensures individual agents focus on specific sub-tasks, and reduces prompt confusion across the network.
3.1.1 Preventing Communication Overhead in Cooperative Networks
A major risk in collaborative mesh networks is communication bloat, where agents exchange infinite loops of natural language updates without reaching a conclusion. To mitigate this risk, systems should use rigid data contracts—such as strict JSON or Protocol Buffers—over dedicated message brokers like RabbitMQ or Apache Kafka. This ensures every transaction matches a known, typed schema that the receiving agent can parse instantly without running costly inference steps just to understand the data format.
3.1.1.1 Routing and Handoff States
Enforcing code-defined routing state machines ensures that task handoffs between agents follow clear, audited pathways. For example, when a financial analysis agent completes data extraction, the system state machine routes that output to a validation agent automatically, rather than letting the initial agent decide where to send the data next. This approach guarantees clean, auditable step-by-step trace histories across the entire application.
Executive Synthesis: High-ROI Operational Scaling
Decoupling monolithic tasks into discrete, specialized agent networks directly impacts long-term operational costs. By isolating agent responsibilities, enterprises can swap out individual models, update specific domain prompts, and scale distinct infrastructure components independently without rebuilding the entire system. This architecture reduces computing overhead, limits expensive model upgrades, and creates an adaptable digital ecosystem that easily integrates new foundation models as they hit the market.
4. State Management and Advanced Memory Subsystems
An agent’s capacity to resolve long-horizon objectives depends heavily on how it manages its state and context across time boundaries. Effective systems isolate immediate session tracking from long-term storage layers.
| Memory Layer | Storage Mechanism | Context Optimization Strategy |
|---|---|---|
| Short-Term Memory | Redis state serialization and local variables | Sliding token buffers and structured summaries |
| Long-Term Memory | Vector databases and semantic embeddings | Automated background log cleanup and pruning |
- Sliding Token Windows: Retaining recent interaction logs while archiving older conversation histories.
- State Serialization: Storing session states in external databases to support instant system recovery.
- Semantic Vector Storage: Utilizing vector databases to retrieve relevant domain information dynamically.
4.1 Architectural Memory Management and Token Optimization
Managing an agent’s memory across extended operational sessions requires balance between raw history tracking and context window boundaries. As transactional logs expand, passing full chat histories to the model causes token bloat, increases API costs, and dilutes prompt focus. Research from Stübinger (2026) highlights that memory tracking systems must treat short-term memory as a dynamic, volatile cache while offloading persistent state variables to stable external databases. This separation ensures context windows stay optimized and relevant.
4.1.1 Automated Background Reflection Loops
To keep long-term vector storage accurate and relevant over time, systems must implement automated, asynchronous reflection loops. Instead of dumping raw execution logs directly into vector databases, a background routine periodically scans transaction histories, extracts key insights, removes redundant entries, and indexes clean semantic embeddings with descriptive metadata tags. This background optimization prevents old or conflicting interaction logs from cluttering future data retrieval passes.
4.1.1.1 Vector Database Schema Optimization
By enforcing metadata tagging and filtering on long-term vector databases, agents can target specific information scopes instantly. Restricting semantic searches to relevant metadata buckets prevents the model from pulling in unrelated data points, lowering inference costs while improving response accuracy across long-horizon workflows.
Commercial Implication: Lowering Computing Overhead and Protecting Data Assets
Optimizing agent memory architectures directly lowers the cost of long-running enterprise AI setups. Implementing structured token management and automated history summary routines reduces data transmission overhead, resulting in substantial savings on monthly cloud API costs. Furthermore, offloading session state to secure external databases protects business data assets from unexpected system crashes, ensuring high availability and seamless data persistence across all active applications.
5. Guardrails, Determinism, and Runaway Execution Defense
Deploying autonomous systems into production environments requires robust validation guardrails. These safety layers must sit at both ingress and egress boundaries to block prompt injection and capture malformed tool payloads before execution.
| Risk Category | Target System Operations | Production Guardrail Blueprint |
|---|---|---|
| Low Risk | Read-only API calls, local structural formatting | Automated execution with standard rate limits |
| Medium Risk | Database updates, file edits, system alerts | Declarative validation schemas and check rules |
| High Risk | Code sandbox execution, financial transactions | Mandatory Human-in-the-Loop approval screens |
- Ingress Scanning: Filtering inbound data payloads to detect and block malicious prompt injection attempts.
- Egress Validation: Verifying generated tool arguments against rigid schemas before executing commands.
- Loop Counter Caps: Halting active processes instantly if consecutive self-correction loops exceed a safe threshold.
5.1 Mitigating Runaway Self-Correction Loops
A common failure pattern in agentic loops occurs when an agent repeatedly encounters a tool error or a failed validation check, trapping it in an expensive, infinite loop of self-correction attempts. As discussed by Khalid (2025), unchecked agent autonomy can create severe security vulnerabilities and cause unpredictable operational costs. To prevent these runtime issues, developers must implement strict, code-driven execution limits and token caps directly within the orchestrator framework.
5.1.1 Implementation of Safe Fallback Frameworks
When an agent fails to complete a task within a set number of processing steps, the orchestrator must halt the loop and route the current state to an alert queue or a human reviewer. This prevents the agent from continuing to consume compute tokens while stuck, protecting production systems from runaway API billing and ensuring complex issues are safely handed off for manual support.
5.1.1.1 Sandboxed Code Isolation Environments
Any agent tasked with writing or running dynamic code must operate within a completely sandboxed execution environment, such as a secure Docker container or an isolated AWS Lambda instance. This environment must enforce strict resource boundaries, block access to local file networks, and disable unapproved outbound web connections to ensure the host system remains safe from unauthorized activities.
Commercial Implication: Risk Management and Cost Predictability
Deploying robust validation guardrails and automated execution limits helps businesses manage the financial and operational risks of running AI systems. Setting hard token caps and loop limits eliminates the risk of unexpected billing spikes, ensuring predictable IT infrastructure costs. Additionally, keeping high-risk actions under strict human-in-the-loop approval gates allows enterprises to adopt autonomous workflows confidently, maintaining high security standards and regulatory compliance across all operations.
6. Comprehensive Production-Grade System Implementation
The code sample below provides a production-ready template for a single-agent orchestrator. It features input data sanitization, rigid data contracts backed by Pydantic, explicit loop counters, and robust error handling routines.
import os
from typing import Dict, Any, List
from pydantic import BaseModel, Field
# =====================================================================
# 1. STRUCTURAL DATA SCHEMAS
# =====================================================================
class AgentState(BaseModel):
"""Tracks global session telemetry and transaction histories."""
session_id: str
task_objective: str
execution_steps: List[Dict[str, Any]] = Field(default_factory=list)
current_iteration: int = 0
max_iterations: int = 5
is_complete: bool = False
extracted_data: Dict[str, Any] = Field(default_factory=dict)
class ToolPayload(BaseModel):
"""Enforces strict structural boundaries for external tool interactions."""
target_api: str
query_parameters: Dict[str, Any]
# =====================================================================
# 2. CORE ORCHESTRATION ENGINE
# =====================================================================
class ProductionAgentController:
def __init__(self, state: AgentState):
self.state = state
def run_perception_layer(self, raw_input: str) -> str:
"""Sanitizes inputs to prevent prompt injection and structural anomalies."""
sanitized = raw_input.strip().replace("<script>", "")
return f"PROCESSED OBJECTIVE: {sanitized}"
def mock_cognitive_inference(self) -> Dict[str, Any]:
"""Simulates internal reasoning loops and execution path selections."""
if self.state.current_iteration >= 3:
return {
"intent": "final_delivery",
"output": {"status": "success", "resolved_payload": "Data payload validated."}
}
return {
"intent": "tool_call",
"payload": {"target_api": "enterprise_ledger", "query_parameters": {"account_id": "ACC-99"}}
}
def execute_grounded_tool(self, tool_action: ToolPayload) -> str:
"""Executes external actions within an isolated validation context."""
if tool_action.target_api == "enterprise_ledger":
return '{"execution_result": "Success", "balance_records": [10450, 22000]}'
return '{"execution_result": "Error", "details": "Unknown system endpoint"}'
def step(self) -> None:
"""Executes a single, deterministic step in the state transition graph."""
if self.state.current_iteration >= self.state.max_iterations:
self.state.is_complete = True
self.state.extracted_data = {"status": "failed", "error": "Max loop counter exceeded."}
return
self.state.current_iteration += 1
reasoning_outcome = self.mock_cognitive_inference()
if reasoning_outcome["intent"] == "tool_call":
validated_tool = ToolPayload(**reasoning_outcome["payload"])
tool_response = self.execute_grounded_tool(validated_tool)
self.state.execution_steps.append({
"loop_step": self.state.current_iteration,
"action": validated_tool.model_dump(),
"response": tool_response
})
elif reasoning_outcome["intent"] == "final_delivery":
self.state.is_complete = True
self.state.extracted_data = reasoning_outcome["output"]
# =====================================================================
# 3. RUNTIME EXECUTION
# =====================================================================
if __name__ == "__main__":
initial_state = AgentState(
session_id="tx-8801",
task_objective="Reconcile quarterly accounts ledger entries."
)
orchestrator = ProductionAgentController(state=initial_state)
print(f"Initializing Workflow: {orchestrator.state.task_objective}")
while not orchestrator.state.is_complete:
orchestrator.step()
print(f" -> Iteration {orchestrator.state.current_iteration} complete.")
print("\nFinal State Matrix:")
print(orchestrator.state.model_dump_json(indent=2))
6.1 System Architecture Review
The Python implementation above illustrates how to isolate an agent’s cognitive choices from the application’s global control flow. By enforcing data tracking through Pydantic models, the orchestrator handles state updates deterministically, ensuring the agent remains within its defined processing limits. For deeper technical strategies on managing structured state code, consult the official documentation at the Pydantic Developer Network.
Commercial Implication: Scalable, Audit-Ready Architecture
Building agent architectures with clean serialization layers ensures that all system operations are fully auditable and ready for enterprise regulatory reviews. Since every state adjustment, tool query, and external API result is logged as a separate data entry, companies can easily maintain comprehensive audit histories. This structural transparency simplifies regulatory compliance, reduces system debugging time, and provides an efficient platform for ongoing optimization and scaling.
7. Evaluation Metrics, Observability, and Telemetry Standards
Evaluating autonomous, multi-step systems requires moving beyond traditional static validation testing. True operational clarity demands continuous monitoring across processing times, token costs, and full reasoning path histories.
| Telemetry Focus | Key Metrics Monitored | System Optimization Target |
|---|---|---|
| Execution Tracing | Step-by-step reasoning steps and tool logs | Identifying and fixing structural routing loops |
| Token Tracking | Inference tokens consumed per execution phase | Optimizing systemic prompts to control runtime costs |
| Latency Mapping | Model inference times vs external endpoint delays | Removing delays in database and API connections |
- Assertive Validation: Confirming that generated tool payloads match exact schema models and type configurations.
- Simulation Sandboxes: Testing complete agent workflows against mock layers before deploying to live systems.
- LLM-as-a-Judge: Leveraging specialized models to evaluate qualitative metrics like context relevance and safety compliance.
7.1 Production Trace Ingestion and Performance Monitoring
Maintaining complete visibility over complex agent networks requires tracking and logging every individual step within an agent’s execution path. Because traditional validation datasets cannot fully capture the dynamic behavior of interactive multi-step flows, engineering teams must deploy advanced observability stacks. As highlighted by Khalid (2025), monitoring these system trajectories in real time helps identify performance drops early, catches edge-case validation errors, and highlights optimization targets across the entire infrastructure.
7.1.1 Advanced Multi-Tier Evaluation Strategies
To ensure high operational quality, production-grade applications must run a multi-tier testing strategy. This includes automated unit tests to verify data structures, integration tests in simulation environments to check agent navigation logic, and automated evaluator models to judge final output quality. For details on establishing secure open-telemetry standards for AI systems, visit the OpenTelemetry Monitoring Framework.
7.1.1.1 Latency Optimization Protocols
Breaking down latency metrics between model inference times and external API calls helps engineers isolate performance bottlenecks quickly. If telemetry data shows model response times are within normal parameters but external database connections are slowing down, teams can optimize those database queries or implement caching layers without rewriting core prompt logic.
Executive Synthesis: Compute Efficiency as a Competitive Edge
Implementing comprehensive telemetry frameworks transforms system observability from a standard maintenance cost into a valuable operational asset. Continuous performance monitoring gives businesses the data required to refine prompts, optimize context sizes, and transition workloads to faster, more cost-effective models safely. This ongoing tuning reduces computing overhead, increases transaction throughput, and ensures the system remains reliable and efficient as its adoption grows across the enterprise.
8. Comprehensive Operational Blueprint Reference Checklist
This reference checklist defines the core engineering standards required to build, secure, and monitor production-grade autonomous agent frameworks.
- ☐ Structural State Isolation: Ensure all session state and telemetry parameters are serialized directly to persistent databases (like Redis or PostgreSQL) instead of leaving them in the model’s raw chat logs.
- ☐ Deterministic Graph Control: Enforce code-driven state machines to govern all routing and step transitions, keeping model intervention strictly localized.
- ☐ Runaway Loop Interceptors: Deploy hard caps on consecutive correction iterations and max session token budgets to prevent infinite billing loops.
- ☐ Granular Role Allocation: Structure individual agents with a narrow task scope, clean system prompts, and explicit tool permissions to eliminate prompt confusion.
- ☐ Sandboxed Tool Environments: Run all untrusted, dynamically generated code within isolated sandboxes that restrict file system access and unapproved external network connections.
- ☐ Multi-Tier Telemetry Tracking: Implement detailed trace logging for all internal reasoning thoughts, tool calls, and execution latencies using established OpenTelemetry standards.
References
Buyya, R. (2026). Agentic Artificial Intelligence (AI): Architectures, Taxonomies, and Evaluation of Large Language Model Agents. arXiv. https://arxiv.org/abs/2601.12560
Khalid, O. (2025). Agentic AI: A Review, Applications, and Open Research Challenges. Preprints.org. https://www.preprints.org/manuscript/202512.0592
Pati, A. K. (2025). Agentic AI: A Comprehensive Survey of Technologies, Applications, and Societal Implications. IEEE Xplore. https://ieeexplore.ieee.org/document/11071266
Stübinger, J. (2026). Understanding AI Agents—A Data-Driven Literature Review. MDPI. https://www.mdpi.com/2227-7390/14/9/1478